随着 HBM4 时代的到来,SK 海力士和美光为 2025 年底至 2026 年的产量提升做准备,现在是探索 HBM(高带宽内存)的构建方式、其关键优势和相关技术以及为什么其制造复杂性导致高成本的理想时机。以下是要点的快速总结。
HBM 内部:成分和主要优势
随着 AI 模型变得越来越复杂(同时处理密集训练和实时推理),它们需要能够在三个方面提供内存:大小、速度和效率。虽然 SRAM 在速度方面表现出色,但在容量方面存在不足,但传统 DRAM 提供充足的存储空间,但缺乏足够的带宽。HBM 成为最佳选择,在容量和速度之间实现最佳平衡。
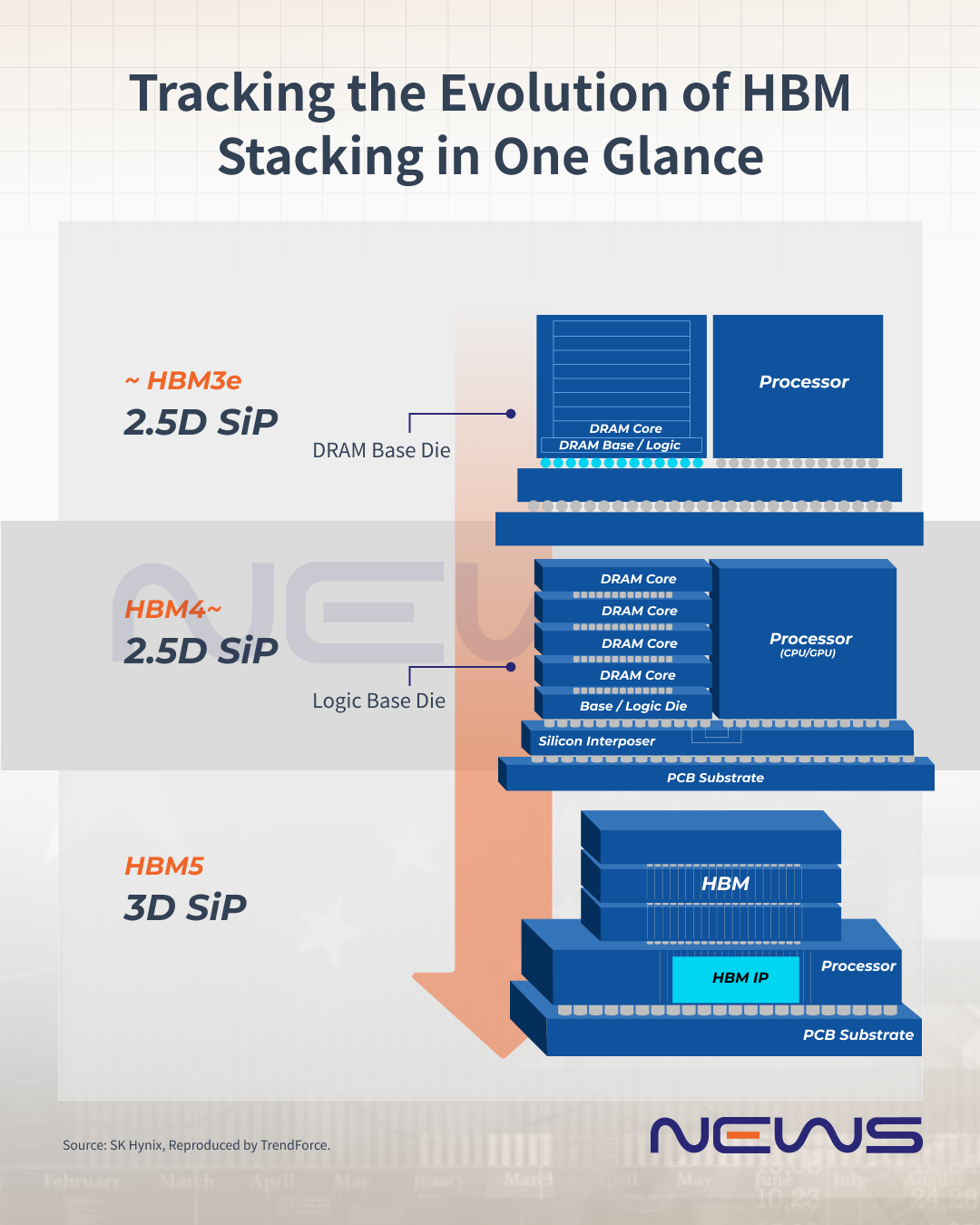
HBM 通过其独特的堆叠架构实现了这一点:多个 DRAM 芯片构建在逻辑(基本)芯片之上,通过数千个并联互连连接。整个堆栈通过封装基板上的硅中介层连接到 xPU,通常与 NVIDIA 等 GPU 配对。
该架构具有几个关键优势。首先,能效:HBM 和 xPU 之间的紧密集成使数据路径保持短,从而降低功耗。第二,海量吞吐量。
相比之下,HBM4 通常比 DDR4 少 40-50% 的功耗来实现相同的带宽。虽然 DDR4 模块的最大速度约为 25.6 GB/s,但单个 HBM4 堆栈可提供超过 1 TB/s 的带宽,这对于需要快速访问海量数据集的工作负载至关重要。
打破记忆墙:为什么 HBM 为人工智能时代提供动力
在生成式AI时代,训练一个ChatGPT规模的模型通常需要数万个GPU同时工作。然而,虽然 GPU 计算能力在过去 20 年中提高了 60,000 倍,但 DRAM 内存带宽仅提高了 100 倍,从而形成了所谓的“内存墙”。简而言之,无论 GPU 处理速度有多快,如果内存无法足够快地提供数据,它就会成为瓶颈。
HBM采用垂直堆垛结构,正是为了突破这一障碍而开发的。它就像一座摩天大楼,层层叠叠的 DRAM 芯片层层叠叠。从技术上讲,每个 DRAM 芯片的厚度约为 30-50 μm,通过硅通孔 (TSV) 和微凸块连接到底层逻辑基座,最后通过硅中介层连接到 GPU。
这种架构使 HBM 能够同时通过数千个“高速通道”传输数据,提供远超传统 DDR 内存的带宽。
创新的代价:HBM 的工程挑战
然而,建造这样的摩天大楼成本很高。根据TrendForce 集邦咨询的数据,HBM3e 已经以估计 20% 的价格溢价推出,而 HBM4 增加的复杂性预计将推动该溢价超过 30%。
TrendForce集邦咨询指出,较高的成本来自HBM4更复杂的芯片设计,该芯片设计扩大了芯片尺寸以适应I/O数量的显着增加。此外,一些制造商正在转向基于逻辑的基础芯片架构以进一步提高性能,这两个因素都导致了更高的生产成本。
值得注意的是,堆叠复杂性仍然是每一代新 HBM 的主要障碍。随着层数增加到 12 层甚至 16 层,TSV 的产量成为一个关键瓶颈。
为了应对这些挑战,不同的制造商采取了不同的方法。SK海力士利用其MR-MUF(质量回流模压底部填充)技术处于领先地位,而三星和美光则继续依赖TC-NCF(非导电膜热压缩)方法。
据SK 海力士称,自 2019 年以来,MR-MUF 已应用于该公司的 HBM2 产品,使该公司在竞争中脱颖而出。这项技术的工作原理类似于“二合一”过程,将芯片连接和保护填充结合在一个步骤中。传统方法就像先建房子,然后修补裂缝,而 MR-MUF 更像是在建造时密封裂缝——更快、更坚固,而且不易出现问题。
简单来说,质量回流焊熔化堆叠芯片之间的凸块以连接它们,而模制底部填充材料则用保护材料填充间隙,从而提高耐用性并有助于散热。这种组合方法对于具有苛刻热要求的高层、高带宽应用(如 HBM)特别有效。
与 NCF 相比,MR-MUF 的导热系数大约是 NCF 的两倍,这对生产速度和产量都有重大影响。
然而,混合键合——通过直接连接芯片而没有凸块——可以实现更薄的堆栈、更多的层数、更少的信号损耗和更高的良率。因此,主要的 HBM 制造商正在考虑是否在 HBM4 16hi 堆栈产品中采用混合键合,但已确认计划在 HBM5 20hi 堆栈一代中实施该技术。
HBM4 基芯片:为什么内存制造商转向代工厂
尽管如此,堆叠 DRAM 层只是一个开始;下一个挑战是在高度精确、深厚的基础上构建它们,就像设计摩天大楼一样。
这在 HBM4 时代极为重要,因为该产品需要一个称为逻辑芯片的专用基础。引人注目的是,这个基础必须处理 2,000 多个精确的连接点(从 1,024 到 2,048 个 I/O 计数)——想象一下一座需要 2,000 条单独的公用事业线路的建筑物——互连间距仅为 6-9 微米,大约是人类头发的 100 倍。
习惯于建造“住宅”(标准内存)的传统内存制造商突然面临着建造这些超深摩天大楼地基的几乎不可能的任务。由于购买数十亿美元的超精密挖掘设备只是为了偶尔挖掘这样的地基在经济上根本不可行,因此他们转向具有专业知识的代工厂,就像台积电一样。
以台积电为例。正如TechNews所指出的,这家代工巨头拥有最先进的工具(N5 和 N12FFC+ 工艺),因为其 N12FFC+ 工艺可以构建 12 堆栈 (48GB) 或 16 堆栈 (64GB) 内存“建筑物”,数据传输速度超过 2TB/s——就像安装超高速电梯一样。另一方面,他们的 N5 工艺以 6-9 微米的间距提供更高的精度,从而实现直接键合技术,允许将内存堆栈直接构建在逻辑芯片上。
HBM:仍然是寡头垄断游戏
随着内存巨头为 HBM4 时代做准备,竞相获得 NVIDIA 验证,有一点是明确的:高制造复杂性使 HBM 牢牢掌握在少数关键参与者手中。TrendForce 预计 SK 海力士将在 2025 年以 59% 的出货量领先,而三星和美光将各占 20% 左右。
在即将到来的 HBM4 战场上,NVIDIA 和 AMD 仍然是重量级人物,推动了对内存巨头的需求。NVIDIA 在今年的 GTC 上推出了下一代 Rubin GPU,而 AMD 正在准备将其 MI400 系列作为直接竞争对手——预计两者都将采用 HBM4。
在规格方面,HBM 中的每个 DRAM 芯片通常厚度为 30-50 μm,堆叠通常由 4、8 或 12 个芯片组成。JEDEC已确认 12 高和 16 高 HBM4 堆栈的标称封装厚度均为 775 μm,高于 HBM3 的 720 μm。
另一方面,与前几代产品相比,HBM4 的 I/O 数量翻了一番,从 1,024 个增加到 2,048 个,同时保持高于 8.0 Gbps 的数据传输速率,与 HBM3e 相当。这意味着 HBM4 可以在相同的速度下提供两倍的数据吞吐量,这要归功于其增加的通道数。
随着逻辑芯片成为协作的中心,台积电等代工厂正在发挥越来越重要的作用——与 HBM4 上的 SK 海力士和 HBM4E 上的美光合作——使 HBM4 战场比以往任何时候都更加动态和不可预测。
